

Сохранить память: как веб-архивация спасает от забвения заблокированные медиа и «вымирающие» ссылки
Огромное пространство интернета хранит в себе петабайты информации, но при кажущейся надежности этого хранилища из него в любой момент может исчезнуть что угодно, не оставив и следа. Чтобы сохранить наиболее полную историю современности, придумали веб-архивацию, которая спасает научные статьи от «гниющих» ссылок, а в нынешних реалиях — еще и российские медиа от тотальной ликвидации. Разбираемся, как архивируют веб-сайты и где всё еще можно послушать старые передачи «Эха Москвы».
С конца февраля в России заблокировали уже более 50 сайтов средств массовой информации. На территории страны теперь недоступны без VPN «Радио Свобода»* и «Настоящее время»*, The Village и сайт журналиста и публициста Александра Невзорова, а также многие другие издания. Некоторые сайты, как «Эхо Москвы», были ликвидированы своими создателями, другие, как издание DOXA, кроме блокировки со стороны Роскомнадзора столкнулись с отключением от сервиса Tilda. Под блокировку попали и сайты общественных организаций и политиков, а также группы СМИ во «ВКонтакте» (и даже фан-группа Екатерины Шульман*).
Блокировку сайта в целом достаточно легко обойти за счет VPN-сервисов или браузерных расширений, но, если сайт был удален полностью, никакой VPN получить доступ к его содержимому уже не поможет.
Однако это совершенно не означает, что вся информация, хранившаяся на сайте, исчезла безвозвратно. Ее могли «спасти» специалисты в области веб-архивации.
Веб-архивация: в тени цифрового темного века
Международный консорциум по сохранению интернета определяет веб-архивацию как «процесс сбора фрагментов Всемирной паутины, сохранения их в архивном формате и последующего обслуживания архивов для всеобщего доступа и использования».
Сам консорциум появился лишь в начале двухтысячных, и его задачей стала разработка стандартов архивации сайтов. Как таковое веб-архивирование началось гораздо раньше.
Необходимость сохранения данных, размещенных в цифровой среде, возникла еще в начале 1990-х и была вызвана страхом ученых перед так называемым цифровым темным веком (digital dark age) — периодом, о котором может не остаться практически никаких свидетельств из-за того, что компьютеры банально не смогут прочесть данные, созданные в конце XX — начале XXI века. Так уже случилось с CD-дисками, ведь во многих современных компьютерах и ноутбуках нет дисковода.
То же самое относится и к данным, хранящимся в интернете. Например, в 2019 году одна из первых в мире социальных сетей MySpace из-за смены серверов потеряла все данные пользователей, загруженные с 2003 по 2015 год.
Веб-архивация была призвана устранить эти недоразумения. Возможно, многим знаком сервис Wayback Machine — иногда в «Википедии» некоторые ссылки в конце статьи помечены как «недоступные», а рядом с ними написано «архивировано» и есть другая ссылка, которая ведет на копию этой статьи. В копии тот же текст, те же иллюстрации, та же верстка, что и в оригинале, но только расположена она на сайте Wayback Machine.
Сервис запустили в 2001 году, и принадлежит он НКО Internet Archive («Архив интернета»). В прошлом году «Архиву» исполнилось 25 лет: в середине 1990-х его основал один из создателей предшественницы World Wibe Web — первой поисковой системы WAIS — Брюстер Кейл и его коллега Брюс Гиллиат.
Помимо «Архива» Кейл и Гиллиат создали коммерческую компанию Alexa Internet, которая тоже занималась каталогизацией веб-ресурсов, а за счет своей коммерческой составляющей могла обеспечивать Internet Archive финансово. Назвали Alexa Internet в честь Александрийской библиотеки. Кейл не раз проводил параллель между событиями разных эпох, связанными с утратой исторических памятников, и угрозой цифрового темного века в ближайшем будущем. Так, он писал:
«Манускрипты из Александрийской библиотеки в Древнем Египте исчезли во время пожара. Ранние печатные книги распались на лоскуты. Многие из самых старых кинофильмов были утилизированы из-за содержания в них серебра. К сожалению, история может повториться с развитием интернета».

Уже через год после создания «Архива» и «Алексы» появился специальный браузерный плагин, с помощью которого Alexa сама определяла, какие страницы наиболее ценны для архивации, исходя, например, из посещаемости сайта. В 2003 году к веб-архивации подключили поискового робота Heritrix, написанного на языке JavaScript. У него открытый код, и создатели загрузили его на GitHub.
Роботы, или, как их еще называют, веб-краулеры, работают по самому распространенному принципу веб-архивирования — харвестингу (от англ. harvesting — «сбор урожая»).
Краулеру сначала передают список URL-адресов, по которым находятся нужные для архивации сайты. Робот посылает HTTP-запрос на веб-сервер, а затем как бы «перехватывает» содержимое, передаваемое сервером. HTTP расшифровывается как HyperText Transfer Protocol (протокол передачи гипертекста) — это по своей сути стандартный запрос, который каждый день обрабатывает сервер исходя из того, что мы вбили в поисковую строку Google или «Яндекса».
Параллельно робот еще и создает новый список — он анализирует просмотренные страницы на предмет гиперссылок. По этим ссылкам лежат файлы или целые веб-страницы, которые тоже нужно будет заархивировать. После сбора данных (харвестинга) специальное ПО преобразовывает все файлы в формат ARC (ARChive) — сейчас его уже заменил WARC (Web ARChive).
Однако возможности краулера не безграничны: например, он не сможет заархивировать веб-сайт, если на нем установлено соответствующее ограничение. Это может случиться, если файл защищен паролем или если в файле robots.txt, который лежит в корне сайта и содержит определенные указания для роботов поисковых систем, прописано ограничение на архивацию данных. Кроме того, робот сталкивается с трудностями и при архивировании так называемых динамических веб-сайтов. Динамический сайт состоит из нескольких шаблонов и скриптов, которые хранятся на сервере в виде отдельных файлов или баз данных. Из-за того, что такой сайт не хранится в виде законченной страницы, краулеру тяжелее считывать данные.
Архивация бывает и «со стороны сервера». Харвестинг — это архивация «со стороны клиента»: робот отправляет запрос и получает ответ от сервера. При архивации «со стороны сервера» шаг с HTTP-запросом пропускают, но такой метод требует прямого доступа к серверу, а следовательно, прямого участия компании или организации, чей сайт будет заархивирован.
Почему ссылки вымирают?
Помимо Internet Archive долгое время был востребован сервис WebCite. Он был запущен в 2003 году и быстро завоевал популярность, потому что стал первым инструментом, который архивировал сайты по запросу пользователей.
Создатель WebCite, Гюнтер Эйзенбах, в то время интересовался «вымиранием ссылок»: в журнале Science в 2003 году вышла статья под названием Going, Going, Gone: Lost Internet References. Наверное, она одна из первых четко обозначила проблему, которая возникла в области цитирования из-за «вымерших» или «сгнивших» ссылок. Такая ссылка ведет либо не на ту страницу, URL-адрес которой задавал пользователь, либо вовсе становится недоступной, из-за чего доступ к веб-странице теряется совсем.
Наиболее уязвимы научные работы: «вымершие» ссылки подрывают их доказательную базу. Так, уже в 2016 году 75% ссылок в исследовательских работах больше не указывали на первоисточник, процитированный автором.
То же самое с материалами на сайтах СМИ: чем старше статья, тем больше вероятность, что в ней встретятся битые или вообще «сгнившие» ссылки. Возможно, даже в этом материале уже через год вы найдете такую «вымершую» ссылку.
Обеспокоенный таким «вымиранием» ссылок, одновременно с WebCite Эйзенбах запустил консорциум, к которому могли присоединиться редакции и издательства научных журналов, чтобы архивировать те сайты и веб-страницы, на которые есть ссылки в научных публикациях.
Однако уже в начале 2010-х годов у сервиса появились финансовые проблемы, и с 2019-го WebCite не принимает запросы на архивирование веб-сайтов и доступен только для чтения.
Стратегии веб-архивации
По всему миру есть сотни инициатив, которые создают веб-архивы, занимаются оцифровкой и другими формами сохранения культуры. Они существуют в форме как государственных, так и общественных или частных проектов. Первые — это национальные библиотеки, как, например, Национальная библиотека Австралии и ее архив Pandora. С 1996 года в архив собирают сайты органов государственной власти, культурных учреждений, общественных движений и организаций.
Уже рассмотренный нами Internet Archive как бы симулирует поисковую систему, ориентируясь на цитируемость, — он охватывает практически все популярные страницы в интернете для того, чтобы их заархивировать. Это так называемая ненаправленная веб-архивация. Кроме Internet Archive таким же ненаправленным веб-архивом является, например, Common Crawl. Архивы национальных библиотек работают по другому принципу: это сфокусированные архивы, нацеленные на сохранение сайтов и документов по определенной тематике. Как правило, краулер в этих архивах обходит заданные сайты по несколько раз за определенный промежуток времени. Например, UK Government Web Archive — это веб-архив сайтов всех госслужб Великобритании. Выбранные сайты робот обходит несколько раз в сутки и сохраняет обновления в архив.
Другая стратегия веб-архивации — это тоже выборочное сохранение веб-сайтов и документов, но при этом сам процесс управляется человеком. Зачастую такие проекты по архивации фокусируются на сайтах, которые могут оказаться под угрозой исчезновения.
Так себя позиционирует команда Archive Team:
«Archive Team — это свободный коллектив архивариусов-изгоев, программистов, писателей и болтунов, посвятивших себя спасению цифрового наследия. С 2009 года мы собираем информацию о возможных отключениях, закрытиях, слияниях веб-сайтов и делаем всё возможное, чтобы спасти историю до того, как она будет потеряна навсегда».
Архив исчезающего рунета
В современной России архивацией веб-сайтов занимается АНО «Инфокультура», которая запустила проект «Национальный цифровой архив». В нем уже есть «Консервированное государство» — заархивированные официальные сайты и аккаунты в соцсетях ведомств, органов власти и партий, копии сайтов всех кандидатов в президенты 2018 года.
«„Национальный цифровой архив“ работает по тому же принципу, что и Archive Team, — комментирует директор АНО „Инфокультура“ Иван Бегтин. — Мы стараемся оперативно отслеживать риски и максимально быстро сохранять сайты, которые находятся под угрозой блокировок или исчезновения».
Архив существует как гибридная модель веб-архивации: в распоряжении проекта есть инструменты на открытом коде, как, например, веб-краулер Heritrix. Собираются данные и силами волонтеров проекта, иногда архивами делятся сами создатели сайтов.
Справедливости ради здесь стоит отметить, что многие проекты веб-архивации устроены по такому гибридному принципу. У Internet Archive, например, тоже имеется собственный краулер, к тому же есть возможность создать свой аккаунт и загружать материалы в общедоступные реестры. На главной странице «Архива» есть еще функция Save page now — в специальное окно можно вставить ссылку нужной веб-страницы и сделать ее копию.
У «Национального цифрового архива» только нет краулера, который охватывал бы весь рунет:
«Мы хотели сделать краулер на весь рунет, но это дорого. Это то, на что нам не хватает ресурсов: нам нужен хороший канал, возможность установить и разместить свой сервер или даже несколько серверов. На фоне каких-нибудь государственных расходов это сущие копейки: несколько миллионов рублей в год — и можно обеспечить хотя бы самый базовый функционал. Но даже эти копейки найти достаточно сложно».
В начале марта — на фоне волны блокировок медиа — «Национальный цифровой архив» «перезапустился» в сети: у него появился свой телеграм-канал, в котором рассказывается о самой веб-архивации, уже собранных сайтах и новых задачах.
«Сейчас практически все издания, которые попали под блокировки Роскомнадзора, в поле нашего зрения, — рассказывает Иван Бегтин. — Но мы, как и любой другой такой проект, занимаем крайне нейтральную позицию: то есть, если бы Роскомнадзор или кто-то еще угрожал российским госСМИ, мы их заархивировали бы. Если Роскомнадзор угрожает оппозиционным СМИ — мы оппозиционные СМИ архивируем. В любом случае главный критерий — недопущение исчезновения этих знаний. Какими бы они ни были».
Собранные архивы можно найти в таблице на сервисе Airtable. Там же есть ссылки на сохраненные сайты и проекты «Мемориала»*. Из сайтов медиа, в последнее время попавших под пристальное внимание Роскомнадзора и Генпрокуратуры, здесь уже есть собранные в архив издания Colta и The Insider*, газета «Бумага» и радио «Эхо Москвы», интернет-журналы DOXA и TJournal. Кроме того, есть архивы телеграм-каналов медиа, отдельные сборники некоторых передач «Эха» в формате mp3 и странички СМИ в социальных сетях.
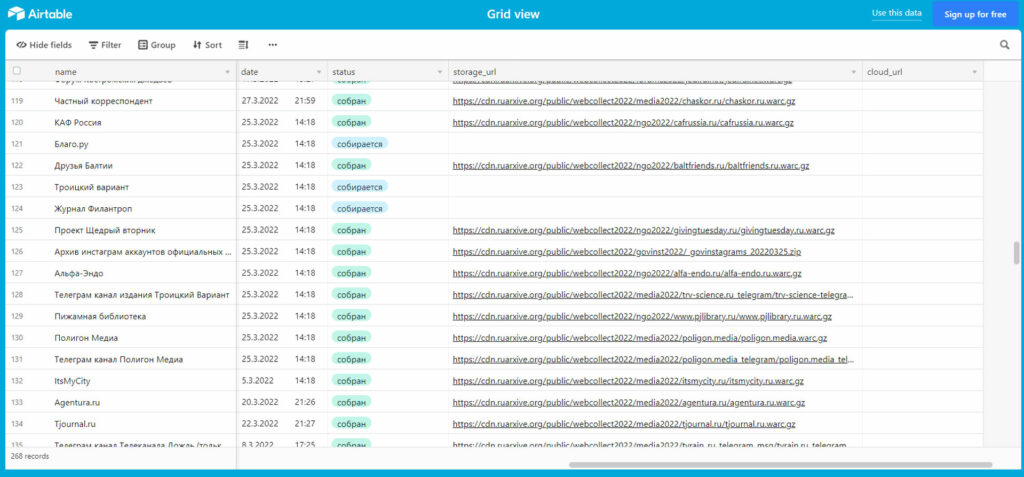
Файлы в формате WARC — архивы веб-сайтов — можно открыть с помощью программы ReplayWeb.page и посмотреть в офлайн-режиме. Остальные архивы — любым архиватором, который работает с форматами ZIP и GZ.
«Политики приходят и уходят, но знания должны сохраняться»
«Если к архивации относиться как к институциональной деятельности, то в России государство этим, к сожалению, не занимается, — говорит Иван Бегтин. — В мире обычно этим занимается государство: либо национальные библиотеки, либо национальные архивы — несколько сотен таких примеров есть в мире. В России, к сожалению, люди, стоящие у власти в области культуры, не мыслят категориями сохранения современности для будущего. В лучшем случае они мыслят сохранением прошлого. Но сохранением современности не мыслит никто. На государственном уровне такого не происходит».
Возможно, вполне логичен вопрос: зачем вообще заниматься веб-архивацией? В чем ценность веб-архивов для будущего? Здесь речь скорее идет о теоретической ценности: сохранение культурного и исторического наследия, информации о цивилизации. Ценность веб-архива для современности тоже сопряжена с культурной значимостью архивируемых документов, а главное — с возможностью их практического применения.
Практическая сторона веб-архивации, по словам Ивана Бегтина, заключается в том, что это «сохранение того, что может в любой момент исчезнуть, но имеет некоторую общественную, культурную значимость». Это СМИ с большой аудиторией, несколькими тысячами посетителей сайта в сутки, которые попали под давление Роскомнадзора. То же самое относится к НКО, особенно к тем, которые имеют статус иностранного агента, выданный Минюстом.
Собранные в ходе веб-архивации данные могут использоваться историками, исследователями в разных областях, журналистами.
«Другая форма применения относится к потреблению культуры и информации. Из российских — это, например, „Эхо Москвы“. Оно было закрыто своим учредителем одномоментно с ликвидацией всего контента, который существовал в открытом доступе, притом что у него была достаточно лояльная аудитория, огромное сообщество, которое крайне заинтересовано в том, чтобы иметь возможность прослушивать многие передачи ретроспективно. Это и авторы передач, и участники, и слушатели. Соответственно, для них веб- или цифровая архивация — возможность получить доступ к тому, что исчезло или может исчезнуть», — отмечает Иван Бегтин.
По его словам, кейс «Эха» был для их проекта очень показателен. Показателен в контексте того, как важно сообщество, которое сейчас формируется вокруг архива:
«Если бы мне в определенный момент 3 марта утром не написали: Иван, пожалуйста, возьмите на архивацию этот сайт срочно, — мы бы этого и не сделали. Не отследили бы. Обычно закрытие проекта длится около месяца-двух — то есть это медленная процедура. Когда предупредили о том, что сайт может исчезнуть за два дня, мы поставили его на консервацию и успели сохранить то, что успели. Это далеко не всё. А есть случаи, когда не успеваем: Znak.com закрылся одномоментно. Он недоступен ни в какой форме. Поэтому мы всячески формируем сообщество для того, чтобы нас заранее предупреждали о том, что может исчезнуть. Ну и, конечно, там формируется пул волонтеров, группы людей, которые сами что-то заархивировали и помогают нам сохранить и дополнить архивы».
«Даже если наши власти считают, что какие-то вещи не должны быть в открытом доступе, они всё равно должны быть заархивированы, они должны быть доступны для исследователей. И это я считаю некоторой безусловной ценностью. Политики приходят и уходят, политики меняются, но знания должны сохраняться», — добавляет Иван Бегтин.