
Сети смысла: где находятся границы языка и почему неправ Хомский
Преподаватель русского языка в Университете Лотарингии Николай Чепурных и докторантка Национального центра научных исследований (CNRS) Франции Полина Михель рассказывают о составлении словарей, трудностях машинного перевода и теории «Смысл ⇔ Текст».
— Расскажите о себе и о научной работе во Франции.
Николай Чепурных: Мы окончили Европейскую магистратуру по лексикографии (EMLex) в Университете Лотарингии, и теперь я преподаю здесь русский. Моя позиция называется «лектор». Обычно это приглашенные на кафедру носители языка, часто, как и я, вчерашние выпускники вуза.
Мои студенты изучают в университете два или три иностранных языка. Скажем, английский — первым, русский — вторым, итальянский — третьим.
Мы с Полиной учились два года при Лаборатории автоматической обработки французского языка (ATILF), но в итоге занимаемся разными языками на современном этапе их развития (условно — с полета Гагарина в космос). Наш руководитель — Ален Польгер, ученик Игоря Александровича Мельчука, автора теории «Смысл ⇔ Текст», почетного профессора Монреальского университета. Ален занимается разработкой лексических сетей для разных языков, и мы входим в группу «Сети русского языка». Руководитель, Светлана Крылосова, и большая часть нашей команды базируются в парижском университете INALCO.

— Что такое лексические сети?
Н. Ч.: Одни словари помогают понимать [слова, их значения и т. д. — Ред.], а другие — изъясняться на иностранном. Нас интересуют прежде всего последние, в частности предназначенные для тех, кто изучает язык. Таких трудов не очень много, нередко это просто коммерческий продукт с минимумом полезной информации для активации речи. Сделать хороший словарь — долго и дорого. Наверное, подобные проекты должны финансировать правительства, заинтересованные в продвижении собственного языка и культуры.
Для тех, кто хочет не только понимать иностранную письменную или устную речь, но и говорить, в словаре должны быть сведения, позволяющие человеку превратить свою мысль в текст.
Допустим, в статье для глагола «покупать», кроме дефиниции, необходимо дать еще и информацию о его связи с другими лексическими единицами языка, значимыми для понимания и, главное, активного использования слова в речи: кто покупает, у кого, что, за сколько, где. То есть должна прослеживаться связь с существительными «покупатель» и «покупка», а также «продавец», «товар», «деньги» и т. д. Так и выстраивается наша сеть.
— То есть облако ассоциаций вокруг каждого понятия?
— Н. Ч.: Можно и так сказать, ассоциативные связи вокруг определенного слова. Подобная репрезентация лексики — это попытка показать, как слова связаны между собой в нашей голове. Обычные словари часто дают скудные и далеко не полные сведения о сочетаемости лексических единиц. Потому у изучающих языки велико искушение просто переводить слово за словом и надеяться, что в итоге получится та же мысль. Но так это не работает, всё устроено гораздо сложнее. Есть явление лексической сочетаемости — коллокации, которые перевести дословно с одного языка на другой не выходит.
Полина Михель: Например, «сильный дождь» дословно будет по-французски forte pluie и по-немецки starker Regen, но по-английски мы, скорее, скажем heavy rain, что, в свою очередь, при буквальном переложении на русский превратится в «тяжелый дождь».
Идея усиления выражается в разных языках неодинаково, и тут не всегда работает дословный перевод.
«Сильная боль», «сильный соперник», «сильная книга» — для каждого из этих выражений найдется свое прилагательное-усилитель в разных языках. Это и есть проблема сочетаемости.
— Как это можно формализовать?
П. М.: В своей магистерской диссертации я работала в том числе и над словарной статьей для прилагательного «сильный». В первую очередь мы разбирались с полисемией, то есть многозначностью, пользовались данными «Национального корпуса русского языка» и выясняли, какие существительные сочетаются с этим прилагательным. Например, сначала в словарной статье идут прямые значения, связанные с физической силой людей и животных, их частей тела («сильные руки, плечи»), затем — метафорические: «сильные моторы», «сильная личность», «сильный соперник», «сильный фильм». Обычно к каждому из них можно подобрать свой синоним. Именно из-за таких семантических нюансов в других языках сочетаемость может варьироваться от существительного к существительному. Например, в русском бо́льшая часть слов, называющих атмосферные явления, эмоции, физические ощущения и пр., сочетается с прилагательным «сильный» в разных его значениях. Такие выводы, к которым мы приходим на основе корпусного анализа, позволяют сделать лексикографическое описание единообразным. Каждое слово в нашей сети соответственно связано с прилагательным, обозначающим усиление.
Н. Ч.: Формализация связей возможна благодаря системе лексических функций, разработанной Игорем Мельчуком и группой московских лингвистов в середине прошлого века.
Они проанализировали ряд языков и поняли, что существует универсальный набор связей между словами, всего около 65.
Каждая из них получила название: например, усиление — это функция Magn. Оно встречается в уже приведенных примерах, а также в следующих выражениях, где мы можем заменить обстоятельство словами «очень» или «сильно»: «страшно устал», «устал как собака», «голодный как волк».
Мельчук и его коллеги пришли к идее лексических функций в рамках работы по созданию машинного перевода в СССР (хотя в США, естественно, тоже существовали подобные проекты — их результаты планировалось использовать в военных целях). Это ключевое открытие в учении Мельчука (а может быть, и главное в лингвистике XX века). Оно послужило основой для создания лексических сетей франко-канадским лингвистом Аленом Польгером. Сейчас в этом направлении работает ряд ученых в Канаде, Европе, в частности в нашей лаборатории ATILF.
— Какие еще есть лексические функции?
П. М.: Самые простые и всем понятные — это синонимы и антонимы. Лексические функции описывают оба вида связей в языке — как парадигматические (например, производные: «реакция», «реагировать», «реактор» и др.), так и синтагматические (сочетаемость слов на уровне фразы: «мощная/сильная/бурная реакция»).
Лексические сети можно сравнить с социальными.
Все пользователи соцсетей теоретически связаны друг с другом, и ни один не находится в изоляции (как и не существует слова, которое не было бы связано с каким-то другим словом). Во «ВКонтакте» пытались в какой-то момент внедрить практику разделения друзей на подгруппы (в нашей аналогии — кластеры слов): «родственники», «коллеги», «лучшие друзья», «друзья по университету» и пр. Эти множества постоянно пересекаются, можно находить знакомых через знакомых твоих знакомых, алгоритмы также сами «предлагали» пользователям друг друга.
Наши лексические сети строятся по похожим принципам: у каких-то слов много связей, например у того же прилагательного «сильный» или у глагола «делать», у каких-то — меньше, и все они доступны изучающему язык. Это можно визуализировать в виде графов, где слова связаны друг с другом и образуют определенные кластеры. Кстати, в теории графов подобная структура называется «Мир тесен».
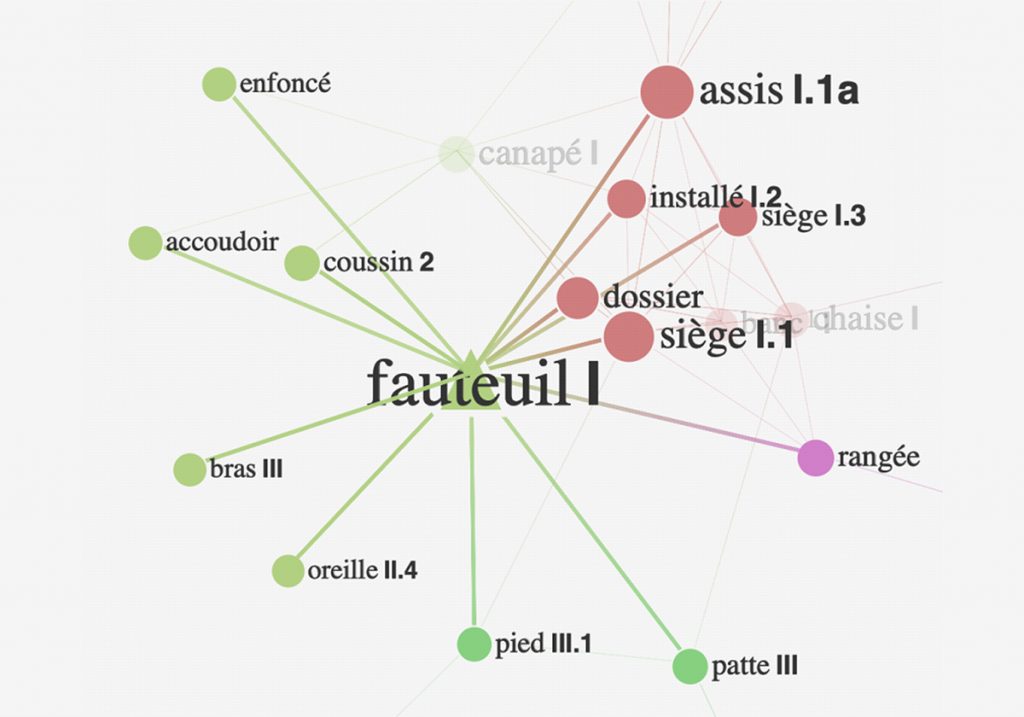
— Как это помогает при изучении языка?
Н. Ч.: С такой сетью можно сделать очень многое — например, с помощью алгоритмов автоматически компилировать разного типа словари, отбирая ту или иную информацию в зависимости от целевой группы (изучающие язык, переводчики и др.).
П. М.: Но все-таки наша главная задача — максимально точно и полно описать языки. Дальше результаты такой работы могут использоваться на практике в разных областях: машинный и обычный перевод, преподавание и изучение языков — и даже языковые игры, такие как шутки, каламбуры, стихи, на которые эти правила тоже распространяются.
Н. Ч.: Кроме того, мы верим, что именно таким образом лексика «хранится» у нас в голове — как сеть из слов, объединенных друг с другом разными типами связи. И доставая из головы одно из них, мы «тянем» вслед за ним ряды тех, в контексте которых оно существует.
Люди владеют языком, когда владеют не словами по отдельности, но разнообразными связями между ними.
Само понятие «слово» не вполне научно. Мы используем термин «лексема», которым называем слово, взятое в одном его конкретном значении. И при дефинировании всякий раз уточняем, в каком именно значении оно употреблено в парафразе.
П. М.: Когда я начинала изучать иностранные языки, то постоянно искала в примерах (порой весьма многочисленных) и текстах, как нужное мне слово связано с другими, как оно употребляется в речи.
Мы же в нашей сети отображаем всё необходимое для изучающего язык, чтобы пользователь мог перейти от смысла, который он хочет выразить, к высказыванию.
Игорь Александрович [Мельчук] вообще считает, что лингвист должен составлять словарные статьи, в этом состоит его работа. Ведь создать хорошую статью — значит максимально точно и полно описать слово и его место в лексической системе языка.
Занимаясь лексикографической практикой, исследователь рано или поздно встает перед необходимостью решать теоретические вопросы. Например, недавно мы разрабатывали статьи для парных глаголов несовершенного вида «лететь» — «летать», «плыть» — «плавать», «тащить» — «таскать» и других подобных (всего в русском 18 таких пар). Как их описывать: как словоформы одного глагола (по типу «делать» — «сделать») — или же как самостоятельные единицы, производящее и производное? И именно лексикографическая практика помогла нам решить теоретический вопрос русской грамматики (об этом скоро можно будет прочитать в нашей статье).
— Не уходит ли такое описание лексики в дурную бесконечность?
Н. Ч.: Не в бо́льшей степени, чем конечен или бесконечен сам язык. Для создания сети нужны рамки, четко обозначенные цели, организованная команда подготовленных лингвистов, обсуждения, рабочие сессии, обмен идеями. Тогда мы получим инструмент для решения конкретных задач в обозримом будущем. Это уже можно увидеть на примере французской сети: государство выделило грант, позволивший собрать команду из восьми специалистов, которые разработали сеть за четыре года.
Существуют и другие лексические базы. Пожалуй, самая известная — WordNet Принстонского университета. Она многое дала программистам, но имела ряд недостатков, поскольку ее создатели сфокусировались в основном на иерархических отношениях синсетов (синонимических рядов). Это признаю́т и сами разработчики: например, между «мячом», «ракеткой» и «сеткой» нет таких связей, которые указывали бы, в свою очередь, на их связь с «теннисом».
Польгер учел опыт в том числе и WordNet’а. На основе теории «Смысл ⇔ Текст» он создал лексические сети, где нет такого сильного акцента на синонимии/антонимии и иерархических отношениях. Последние отражены здесь при помощи семантических этикеток, объединяющих разные части речи. Это гигантский граф с более чем 60 видами связей. Такое полное и точное описание лексики языка — процесс очень трудоемкий, но осуществимый.
Действительно, адепты теории Мельчука сталкиваются с рядом практических трудностей: далеко не все лексикографы готовы тратить столько времени на описание одной единицы, сколько она того требует, особенно если речь идет о многозначных словах и тех, что имеют «много друзей» — связей с другими лексемами языка. Также для работы в сети лингвист должен разбираться и в синтаксисе, и в семантике, и в морфологии, но чаще исследователи специализируются на чем-то одном и не очень интересуются другими аспектами.
Кроме того, необходимо придерживаться целого ряда лексикографических принципов. Один из них — единообразие, которого не встретишь в большинстве существующих изданий. Например, почему в словаре Д. Н. Ушакова есть такие названия статей, как АНГЛИЧАНЕ (мн. ч.) и ЕВРЕИ (мн. ч.), но — АМЕРИКАНЕЦ (ед. ч.)? Почему в «Новом толково-словообразовательном словаре» Т. Ф. Ефремовой мы находим статьи НОСКИ, но — ПЕРЧАТКА?
— Каковы перспективы разработки лексических сетей в русском языке? И сохраняется ли интерес к нему в мире?
Н. Ч.: Вряд ли кто-то во Франции будет финансировать только русский проект — надо добавлять французский и английский языки. В моем случае это органичное дополнение: преподавание русского франкоговорящим, французский тут к месту.
Интерес к русскому языку держится по-прежнему на произведениях Достоевского, Толстого, Чехова и некоторых авторов XX века.
Возможно, отчасти — на воспоминаниях о политической мощи СССР. Также среди учеников есть потомки тех, кто эмигрировал из России в разные периоды. У меня в этом году было почти 100 студентов среди начинающих, которые решили выбрать русский язык третьим иностранным. Второй иностранный он у 40 человек на первом курсе, у 32 — на втором, у 15 — на третьем и еще приблизительно у 15 — в магистратуре. Я тут первый год и пока не знаю динамики этих чисел, но интерес к русскому языку есть.
Как и к проекту, которым мы занимаемся! В прошлом месяце к нам приезжала делегация преподавателей из Тюмени, где сейчас активно развивается ТюмГУ [Тюменский государственный университет. — Ред.]. Там есть заинтересованные в сотрудничестве специалисты.
Также в этом году выделено финансирование на междисциплинарный проект по описанию научной терминологии на основе лексических сетей, в том числе для русского языка в сравнении с французским и английским. Это тема диссертации Полины.
Найти финансирование непросто — даже, например, для немецкого языка. В исследовательском институте IDS в Мангейме занимаются созданием нескольких немецких словарей, и у некоторых проектов есть проблемы, хотя правительство выделяет очень большие деньги на популяризацию своего языка и культуры.
— А российское правительство?
Н. Ч.: Существует фонд «Русский мир», занимающийся популяризацией отечественной культуры и науки, но у нас с ними нет контактов.
— Вы говорили, что именно в виде сети значений язык представлен в человеческом сознании. Как это соотносится с известными идеями Ноама Хомского?
Н. Ч.: Конечно, его теории до сих пор популярны: говорят, самые цитируемые авторы в прошлом веке — это Маркс и Хомский. Студентам, изучающим компьютерную лингвистику, обычно нравится его знаменитое «бессмысленное» предложение: «Бесцветные зеленые идеи спят яростно». Хомский говорит, что можно создать бесконечно много законченных синтаксических конструкций, осмысленных или нет. Ну и что? Вроде как получается, что грамматика у него стоит во главе угла. Мы исходим из того, что первична лексика. Насколько я знаю, Польгер считает путь Хомского тупиковым.
— Как теория и подготовленный материал могут применяться в работе над машинным переводом?
Н. Ч.: Среди других проектов, опирающихся на теорию «Смысл ⇔ Текст», можно назвать, например, лингвистический процессор ЭТАП, который создавал российский лингвист Юрий Апресян.
Опыты по машинной обработке текста при помощи лексических сетей уже проводились, но для перевода необходимо, чтобы они были созданы для нескольких языков одновременно. На данном этапе лингвисты заняты именно этим. Сейчас лучше всего разработана французская сеть, она в свободном доступе, скачать ее можно бесплатно; русская появилась несколько лет назад и активно пополняется; английская пока только создается.
Мы начали заниматься русским языком в магистратуре на практике. Определяли базовые значения слов, для их иллюстрации искали примеры в «Национальном корпусе», причем только в современных текстах. За лето мы вдвоем описали таким образом 3500 лексем.
Помимо лексических функций, мы также занимаемся актантами, или, проще говоря, «участниками ситуации». Основополагающий вклад в разработку этого понятия внес Люсьен Теньер. «X продал товар Z Y-у за сумму денег W». В предложении с глаголом «одолжить» будут уже другие «участники» («X одолжил предмет Z Y-у на период времени T»).
Понимание актантов помогает формулировать мысль. В аспирантуре я как раз хотел бы работать над созданием словаря валентностей для русского и французского языков на базе лексических сетей, описывая именно эти переменные.

— Не слишком ли это сложные задачи, если есть рабочие онлайн-переводчики? Человек сегодня считает, что не обязательно вникать в тонкости речи, когда хоть как-то вычленяется смысл.
Н. Ч.: Онлайн-переводчики используют статистические методы, основанные на анализе огромных многоязычных параллельных корпусов текстов. Постепенно меняются и совершенствуются алгоритмы. Когда разработчики стали задействовать нейросети, качество перевода выросло. Возможно, они и дойдут до такого уровня, когда результат будет очень хорошим, но «магия» таких процессов скрыта от человека-пользователя, непонятна ему. У нас совсем другой подход.
П. М.: Перевод только одна из проблем — еще есть, например, преподавание. Сколько усилий уходит у педагога на подготовку к одному занятию по теме? Он читает множество текстов, разбирает бесконечные примеры, сам интуитивно создает «облака» вокруг слов, ассоциативные ряды, чтобы предоставить ученикам не просто отдельные слова, но слова в контексте других слов, проводится огромная поисковая работа. Если бы существовал ресурс, где лексические единицы и связи между ними были бы описаны, унифицированы, стандартизированы, это в разы облегчило бы рутину и преподавателя, и студента.
Н. Ч.: Получается, мы хотим создать ресурс, о котором сами мечтали, когда начинали учить языки.
Моя цель — систематизировать в словаре валентностей русских слов примеры употребления лексических единиц, создать опору для изучающих иностранный язык, помочь им выразить мысль так же, как это делают его носители.
П. М.: Вообще, вопрос, зачем улучшать процесс перевода и обучения языку, странный. А зачем мы улучшаем качество еды, качество жизни — ведь для «жизни» хватит и того, что было 30, а то и 100 лет назад?
Да, современные лингвистические ресурсы дают некий результат, но этого недостаточно! Почти все мы и наши знакомые когда-либо изучали иностранный язык или несколько, используя существующие инструменты (словари, электронные переводчики). Но опыт и статистика показывают, что это было очень и очень неэффективно: лишь единицы действительно говорят на иностранных языках. Нужны новые средства, новый подход — как преподавателям, так и ученикам.
Наконец, даже если когда-то этот процесс полностью автоматизируют и у каждого в ухе окажется маленький синхронный переводчик, сперва кто-то должен напрячься и максимально подробно и точно описать языки. Чтобы упростить жизнь в будущем, кому-то сейчас нужно проделать еще много сложной работы. Мы можем как минимум не пугаться — и начать ее выполнять.
