
«Крутой data scientist получает как гендиректор средней компании». Эксперт по машинному обучению «Яндекс.Такси» — о том, как данные предсказывают будущее и формируют мир
Такси — это уже не просто способ перемещения из точки «А» в точку «Б», это полноценный сервис, который знает о наших интересах, ритме жизни и даже финансовом положении. Как это работает и где учиться на data scientist, рассказал Виктор Кантор — эксперт по машинному обучению в «Яндекс.Такси».
— Можешь на совершенно примитивном примере рассказать, как работает машинное обучение?
— Могу. Есть пример метода машинного обучения под названием «Решающее дерево», одна из старейших вещей. Давай сейчас сделаем. Допустим, абстрактный человек приглашает тебя на свидание. Что для тебя важно?
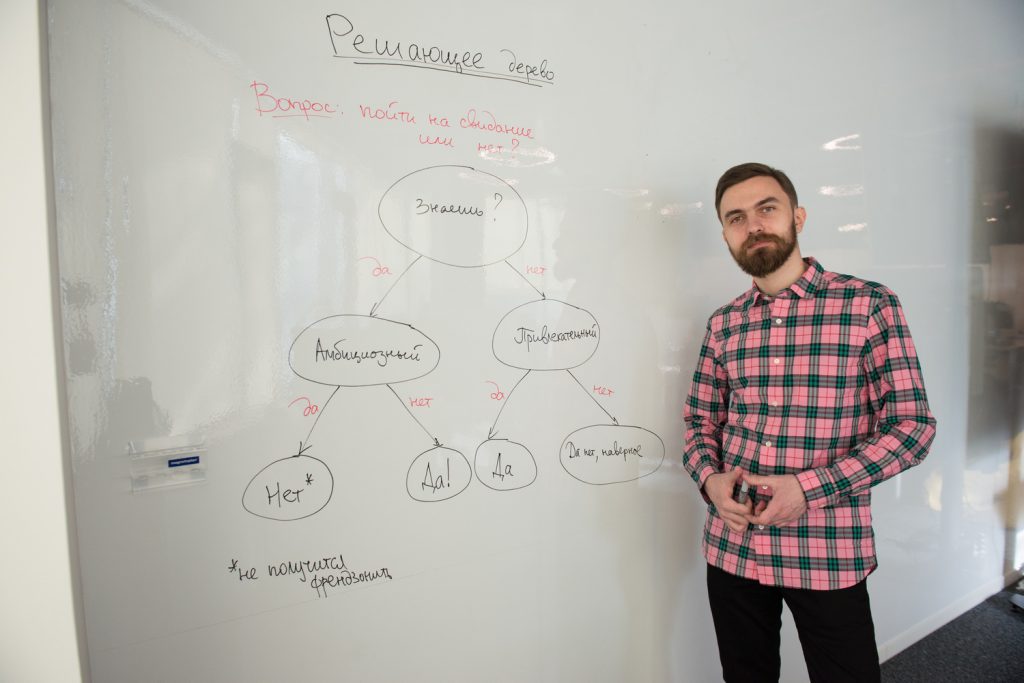
— Во-первых, знаю я его или нет...
(Виктор пишет это на доске.)
...Если не знаю, то надо ответить на вопрос, привлекательный он или нет.
— А если знаешь, то неважно? Кажется, я понял, это ветвь френдзоны! В общем, пишу, если не знаешь и непривлекательный, то ответ «да нет, наверное». Если знаешь — ответ «да».
— Если знаю, тоже важно!
— Нет, это будет ветвь френдзоны.
— Хорошо, тогда давай здесь укажем, интересный или нет. Все же, когда не знаешь человека, первая реакция на внешность, со знакомым мы уже смотрим, что тот думает и как.
— Давай по-другому. Амбициозен он или нет. Если амбициозен, то его будет сложно френдзонить, он же будет хотеть большего. А неамбициозный потерпит.
(Виктор дорисовывает решающее дерево.)
Готово. Теперь можно прогнозировать, с каким парнем ты, скорее всего, пойдешь на свидание. Кстати, некоторые сервисы знакомств прогнозируют такие вещи. По аналогии можно прогнозировать и сколько товаров купят клиенты, и где будут находиться люди в это время суток.
Ответы могут быть не только «да» и «нет», но и в виде чисел. Если хочется более точный прогноз, можно сделать несколько таких деревьев и усреднять по ним. И с помощью такой простой штуки можно фактически предсказывать будущее.
А теперь представь, было ли сложно придумать такую схемку людям двести лет назад? Вообще нет! Эта схемка никакого рокет сайнса в себе не несет. Как явление машинное обучение существует примерно полвека-век. Прогнозировать на основе данных начал Роналд Фишер еще в начале XX века. Он взял ирисы и распределил их по длине и ширине чашелистика и лепестка, по этим параметрам он определял вид растения.
В индустрии машинное обучение стали активно использовать последние десятилетия: сильные и относительно недорогие машины, которые нужны для обработки большого количества данных, например для таких решающих деревьев, появились не так давно. Но все равно дух захватывает: мы рисуем эти штуки для каждой задачи и с их помощью предсказываем будущее.
— Ну, точно не лучше всяких осьминогов-предсказателей футбольных матчей...
— Не, ну куда нам до осьминогов. Хотя у нас вариативность больше. Сейчас с помощью машинного обучения можно экономить время, деньги и повышать комфорт жизни. Машинное обучение несколько лет назад побило человека в вопросе классификации изображений. Например, компьютер может распознать 20 пород терьеров, а обычный человек нет.
— А когда вы анализируете пользователей, каждый человек для вас — набор чисел?
— Грубо говоря, да. Когда мы работаем с данными, все объекты, включая поведение пользователей, описываем определенным набором чисел. И эти числа отражают особенности поведения людей: как часто ездят на такси, каким классом такси пользуются, в какие места обычно ездят.
Сейчас мы активно строим look-alike-модели, чтобы по ним определять группы людей со схожим поведением. Когда мы вводим новую услугу или хотим пропиарить старую, предлагаем ее тем, кому это будет интересно.
Например, вот у нас появилась услуга — два детских кресла в такси. Мы можем заспамить этой новостью всех, а можем адресно сообщить о ней только определенному кругу людей. У нас за год накопилось какое-то количество пользователей, которые в комментариях писали, что им нужно два детских кресла. Мы нашли их и похожих на них людей. Условно, это люди за 30 лет, которые регулярно путешествуют и любят средиземноморскую кухню. Хотя, конечно, признаков куда больше, это я для примера.
— Даже такие тонкости?
— Это нехитрое дело. Все вычисляется с помощью поисковых запросов.
— А в приложении это может как-то работать? Например, вы знаете, что я нищая и подписана на группы вроде «Как выжить на 500 рублей в месяц» — мне предлагают только побитые дешевые машины, подписана на новости SpaceX — и мне время от времени подгоняют Tesla?
— Работать это так может, но подобные вещи в «Яндексе» не одобряются, потому что это дискриминация. Когда персонализируешь сервис, лучше предлагать не самое приемлемое, а лучшее из доступного и то, что человеку нравится. А распределение по логике «этому нужна машина более хорошая, а этому — менее хорошая» — зло.

— У каждого есть извращенные желания, и порой нужно найти не рецепт средиземноморского блюда, а, например, картинки про копрофилию. Персонализация и в этом случае будет работать?
— Всегда есть приватный режим.
Если я не хочу, чтобы о моих интересах кто-то знал или, допустим, ко мне пришли друзья и захотели посмотреть какой-нибудь треш, то лучше пользоваться режимом инкогнито.
Еще ты можешь решать, сервисом какой компании пользоваться, например «Яндексом» или «Гуглом».
— А есть разница?
— Сложный вопрос. Не знаю, как у других, но в «Яндексе» жестко с охраной персональных данных. Особенно контролируют сотрудников.
— То есть если я рассталась с парнем, не смогу узнать, поехал он на эту дачу или нет?
— Даже если ты работаешь в «Яндексе». Это, конечно, печально, но да, не удастся узнать. У большинства сотрудников нет даже доступа к этим данным. Все зашифровано. Все просто: нельзя шпионить за людьми, это личная информация.
Кстати, на тему расставания с парнями у нас был интересный кейс. Когда мы делали прогнозирование точки «Б» — точки назначения в такси, ввели подсказочки. Вот, смотри.
(Виктор заходит в приложение «Яндекс.Такси».)
Например, такси думает, что я дома. Предлагает мне поехать либо на работу, либо в РУДН (я читаю там лекции в рамках курса по машинному обучению Data Mining in Action). И в какой-то момент, разрабатывая эти подсказки, мы поняли, что нужно не скомпрометировать пользователя. Точки «Б» кто-нибудь может увидеть. По этим соображениям мы отказались предлагать места по похожести. А то сидишь в приличном месте с приличными людьми, заказываешь такси, а тебе там пишут: «Смотри, в этом баре ты еще не был!»
— Что за синие точки мигают у тебя на карте?
— Это pickup points. Эти точки показывают, куда удобнее всего вызвать такси. Ведь ты можешь вызвать в такое место, куда будет совсем неудобно заехать. Но вообще, можешь вызвать в любую точку.
— Да, в любую. Я как-то с этим пролетела на два квартала.
— В последнее время были разные сложности с GPS, это приводило к разным веселым ситуациям. Людей, например, на Тверской, навигация перебрасывала через Тихий океан. Как видишь, иногда бывают промахи и побольше двух кварталов.
— А если перезапустить приложение и тыкнуть снова, то цена изменяется на несколько рублей. Почему?
— Если спрос превышает предложение, то алгоритм автоматически формирует повышающий коэффициент — это помогает воспользоваться такси тем, кому важно уехать максимально срочно, даже в периоды высокого спроса. Кстати, с помощью машинного обучения можно прогнозировать, где будет больший спрос через, например, час. Это помогает нам подсказывать водителям, где будет больше заказов, чтобы предложение соответствовало спросу.
— Не думаешь, что «Яндекс.Такси» скоро убьет весь рынок такси?
— Думаю, что нет. Мы за здоровую конкуренцию и не боимся ее.
Сам я, например, пользуюсь разными сервисами такси. Мне важно время ожидания, поэтому смотрю по нескольким приложениям, какое такси приедет быстрее.

— Вы же объединились с Uber. Зачем?
— Это не в моей компетенции комментировать. Я думаю, объединиться — это глубоко разумное решение.
— В Германии один парень установил на дроны ванну и так слетал за бургером. Вы подумывали о том, что настало время осваивать воздушное пространство?
— Про воздушные пространства не знаю. За новостями в духе «Uber запустил такси на лодочках» мы следим, а про воздух ничего не могу сказать.
— А такси-беспилотники?
— Здесь интересный момент. Мы их разрабатываем, но над тем, как именно нужно их использовать, надо думать. Пока еще рано делать прогнозы, в каком виде и когда они появятся на улицах, но мы делаем все, чтобы разработать технологию для полностью автономного автомобиля, где человек-водитель вообще не понадобится.
— Есть опасения, что ПО беспилотников смогут взломать, чтобы управлять машиной удаленно?
— Риски есть всегда и везде, где есть технологии и гаджеты. Но вместе с развитием технологий развивается и другое направление — их защита и безопасность. Все, кто так или иначе занимаются развитием технологий, работают над системами защиты.
— Какие данные о пользователях вы собираете и как вы их защищаете?
— Мы собираем обезличенные данные пользования, например, откуда, когда и куда была совершена поездка. Все важное — хешируем.
— Ты думаешь, из-за беспилотников сократится количество рабочих мест?
— Я думаю, что станет только больше. Все же эти беспилотники тоже как-то надо обслуживать. Это, конечно, немного стрессовая ситуация, менять специальность, но что поделать.
— Греф на каждой своей лекции говорит, что человек будет менять профессию минимум три раза кардинально.
— Я не могу назвать какую-то специальность, которая на века. Разработчик всю жизнь не работает на одном и том же языке и с одними и теми же технологиями. Везде нужно перестраиваться. С машинным обучением я отчетливо ощущаю, как ребята, которые на шесть лет меня моложе, намного быстрее меня соображают. При этом люди в 40 лет или 45 лет ощущают это еще сильнее.
— Опыт уже не играет роль?
— Играет. Но методы меняются, можно прийти в область, где, например, глубокое обучение не использовалось, работаешь там какое-то время, потом методы глубокого обучения внедряются везде, а ты в этом ничего не соображаешь. И все. Твой опыт может быть полезен только в вопросе планирования работы команды, и то не всегда.
— А твоя профессия — data scientist, она востребована?
— На специалистов в data science спрос просто зашкаливает. Очевидно, что сейчас период безумного хайпа. Слава богу, блокчейн немного помог этому хайпу спасть. Специалистов по блокчейну еще быстрее разбирают.
Но многие компании сейчас думают, что если они вложат деньги в machine learning, у них сразу зацветут сады. Это не так. Машинное обучение должно решать конкретные задачи, а не просто существовать.
Бывают случаи, когда какой-нибудь банк хочет сделать рекомендательную систему услуг для пользователей. Спрашиваем: «Вы думаете, это будет экономически оправдано?» Отвечают: «Да нам по фигу. Сделайте. У всех же рекомендательные системы, мы будем в тренде».
Боль в том, что реально полезную для бизнеса вещь нельзя сделать за один день. Нужно смотреть, как будет обучаться система. А она всегда в начале работает с ошибками, ей может не хватать каких-то данных при обучении. Ты исправляешь ошибки, потом снова исправляешь и даже все переделываешь. После этого нужно настроить так, чтобы система работала в продакшене, чтобы была стабильная и масштабируемая, это еще время. В итоге на один проект уходит полгода, год и больше.

Если смотреть на методы машинного обучения как на черный ящик, то запросто можно пропустить, как начинает происходить какая-то чушь. Есть бородатая история. Военные попросили разработать алгоритм, по которому можно анализировать, есть танк на снимке или нет. Исследователи сделали, протестировали, качество отличное, все здорово, отдали военным. Приходят военные и говорят, что ничего не работает. Ученые начинают нервно разбираться. Выясняется, что на всех снимках с танком, которые принесли военные, в углу ручкой была проставлена галочка. Алгоритм безупречно научился находить галочку, про танк он ничего не знал. Естественно, на новых снимках галочек не было.
— Я встречала детей, которые сами свои диалоговые системы разрабатывают. Вы не думали, что уже с детьми нужно сотрудничать?
— Я уже достаточно давно езжу на всякие мероприятия для школьников, читаю лекции про машинное обучение. И, кстати говоря, одну из тем меня научила рассказывать десятиклассница. Я был абсолютно уверен, что мой рассказ будет хорош и интересен, горд собой, начал вещать, и девочка такая: «А, эту штуку мы хотим минимизировать». Я смотрю и думаю, а действительно, зачем, и правда можно минимизировать, и особенно доказывать тут нечего. Уже прошло несколько лет, сейчас она наши лекции слушает как студент «Физтеха». У «Яндекса», кстати, есть «Яндекс.Лицей», где школьники могут получить бесплатно базовые знания по программированию.
— Посоветуй вузы и факультеты, где сейчас преподают machine learning.
— Есть МФТИ, факультеты ФИВТ и ФУПМ. Еще в «Вышке» есть замечательный факультет компьютерных наук, в МГУ на ВМК есть машинное обучение. Ну, и сейчас в РУДН можно послушать наш курс.
Как я уже сказал, профессия эта востребована. Очень долгое время люди, получавшие техническое образование, занимались совершенно другими делами. Машинное обучение — замечательный пример, когда все вещи, что учили люди с техническим образованием, сейчас прям нужны, полезны и хорошо оплачиваемы.
— Насколько хорошо?
— Назови сумму.
— 500 тысяч в месяц.
— Можешь, только не будучи рядовым data scientist. Но в каких-то компаниях совсем-совсем стажер может получать за несложную работу тысяч 50. Тут очень большой разброс. Вообще, зарплату крутого data scientist можно сравнить с зарплатой гендиректора какой-то средней компании. Во многих компаниях помимо зарплаты на работника сваливается еще много плюшек, и если видно, что человек пришел не за тем, чтобы хороший бренд в резюме вписать, а реально работать, то у него все будет хорошо.