Цифровое шарлатанство, стихи о Крыме и китайские единороги. Как Московско-тартуская школа по digital humanities готовит «вычислительных гуманитариев»
Можно ли научить компьютер понимать поэзию? Как вычислить различия между бульварной прозой и высокой? Какие эмоции испытывали авторы дневников времен Большого террора? Всеми этими вопросами занимаются специалисты в области digital humanities. Корреспондентка «Ножа» посетила ежегодную Московско-тартускую школу по цифровым гуманитарным исследованиям и попыталась разобраться, появятся ли у наук о культуре принципиально новые возможности благодаря современным вычислительным методам.
Что такое digital humanities?
Словосочетанию digital humanities, которое можно неформально понимать как «обработка гуманитарных данных вычислительными методами», исследователи пытались дать строгое определение уже 817 раз — особого успеха, впрочем, в этом не добились. Это одна из четырех проблем молодой науки, и организатор центра digital humanities ГУ ВШЭ Анастасия Бонч-Осмоловская начинает с нее открывающую лекцию школы.
Ситуация предсказуема: соединить оцифровку текстов, создание баз данных в самых разных гуманитарных областях, а также многообразие методов data science (от корпусной лингвистики до распознавания эмоций по видео и автоматического сбора биографических данных) в какую-либо единую область с внятным предметом исследования почти невозможно.
Попытка применять точные методы в гуманитарных науках отнюдь не нова — этой традиции, восходящей по крайней мере к русским формалистам, уже более ста лет. Но лишь в последние 15 лет развитие вычислительной техники позволило перейти от ручного изучения отдельных примеров к вычислительному исследованию огромных массивов текстов, насчитывающих многие миллионы слов. При ближайшем рассмотрении цифровые гуманитарные науки немедленно распадаются на разработку тех или иных методов или программных систем, которой занимаются специалисты, связанные с computer science, и на применение этих методов и систем в конкретных задачах, чем занимаются овладевшие новыми техниками специалисты в соответствующих гуманитарных областях.
Может быть интересно:
Впрочем, пока область молода — число гуманитариев, применяющих современные вычислительные методы, невелико, а сами они довольно разносторонни. Так что digital humanities на поверку оказывается не отдельной дисциплиной, но сообществом заинтересованных людей, которые смогли организовать свои исследовательские центры в университетах по всему миру. Именно на этой точке зрения и остановилась Анастасия Бонч-Осмоловская.
Следующие две проблемы цифровых гуманитарных наук, разобранные лекторкой, достаточно стандартны. Первая из них связана с завышенными ожиданиями от современных технологий и баз данных, зачастую оказывающихся ненадежными, медленно функционирующими, неполными и дорогими в обслуживании — набор проблем, знакомый всем, кто работает с информацией.
Другая проблема — засилье шарлатанских вау-эффектов: за обилием ярких картинок и красивых видео в «продающих презентациях» суть работы оказывается почти невозможно уловить. Это тоже обычная ситуация в прикладных (да и не только!) науках. Попытка получше упаковать и поярче продать тривиальность — неизменный спутник любой современной дисциплины, вынужденной «торговать своей необходимостью» с грантодателями, представителями индустрии и широкой общественностью.
Красивая обертка лучше работает на краткосрочное привлечение внимания, чем на глубокое содержание, а значит, и те, кто перераспределяют собственные интеллектуальные ресурсы в ее пользу, нередко оказываются лучшими научными «спринтерами». Когда хайп спадет, карьера будет уже сделана, а при некоторой сноровке можно оседлать и следующую волну.
«Теория систем», «нечеткая логика», «теория хаоса» — самые громкие из великого множества подобных рекламных пузырей, накрывавших прикладные науки второй половины прошлого столетия.
Надо сказать, упоминания «шарлатанских вау-эффектов» задели слушателей, и едва ли не каждый последующий выступающий стеснительно говорил и о своем собственном возможном «шарлатанстве».
Последний поднятый Анастасией Бонч-Осмоловской вопрос, связанный с качеством и уровнем исследований и результатов в современном цифровом литературоведении — той области digital humanities, которой была посвящена большая часть школы, — оказывается куда более глубоким. Американская исследовательница Нан Зет Да недавно разобрала 15 работ в области цифрового литературоведения и выявила в них глубочайшие проблемы не только на уровне постановки задач или нетривиальности выводов, но даже в корректности обработки статистических данных.
Нан Зет Да утверждает следующее:
- Обработка данных зачастую проводится безграмотно: многие «цифровые литературоведы» плохо разбираются в математической статистике, в то время как сторонники новой дисциплины продолжают привлекать неофитов низким порогом входа.
- Существующие методы компьютерного анализа текстов сводятся к подсчету частоты слов или их фиксированных цепочек.
- Выводы, получаемые при компьютерном анализе текстов, часто плохо воспроизводимы (например, при смене выборки) либо тривиальны.
- Полученные результаты почти ничего не объясняют.
Противоположная сторона оправдывается: частотный анализ является лишь базовой техникой, первым шагом в исследовании корпусов литературных текстов, никак не претендующим на окончательность. Современные компьютерные методы могут обрабатывать гораздо бо́льшие массивы текстов, чем человек, но умеют производить с ними лишь простейшие операции.
Digital humanities на практике
В качестве контрпримера, показывающего потенциал эволюции цифрового литературоведения, Бонч-Осмоловская напомнила о классическом исследовании В. Я. Проппа «Морфология сказки» (1928) и работе Венди Ленерт Plot Units and Narrative Summarization (1981), которые описывают сюжет художественного произведения через формализованные последовательности действий персонажей.
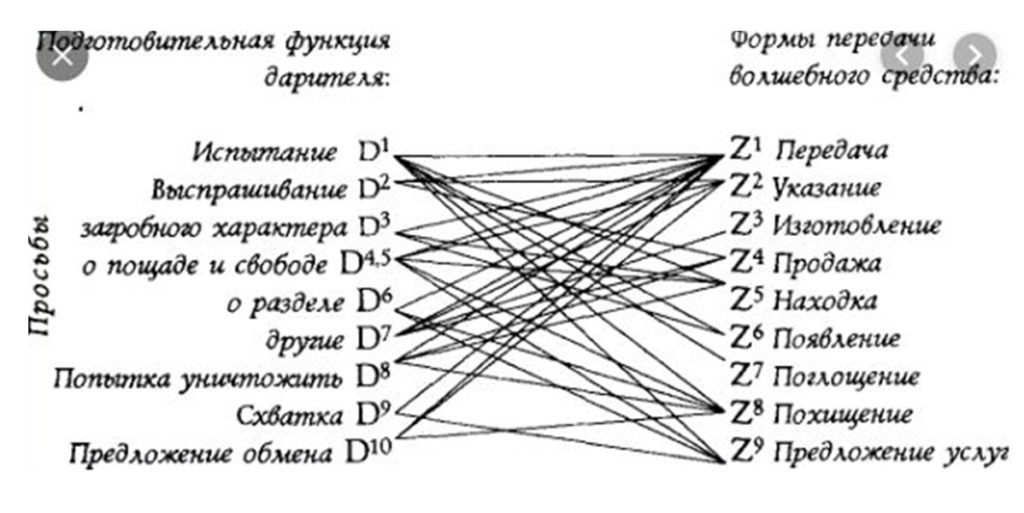
В качестве примера развития метода Бонч-Осмоловская привела доклад исследователей из Университета Беркли, посвященный автоматическому детектированию событий в литературных произведениях.
Авторы доклада вручную разметили начальные 2000 слов 100 англоязычных романов, пометив в них «триггеры событий» (то есть отдельные глаголы, существительные и прилагательные, выражающие конкретные, совершенные в прошлом или настоящем действия). При помощи нейросети, обученной на этой выборке, исследователи определяли в дальнейшем события романов, оказывавшиеся «реальными» — то есть те, что приводили героев изменению их состояния или к выражению сильных эмоций либо являлись следствием некой причины, которую можно найти внутри того же самого предложения.
Исследователи сделали вывод, что авторы бульварных романов наполняют произведение множеством событий, в то же время создатели высокой литературы могут этого и не делать.
Утверждение это, на наш взгляд, довольно ожидаемо и скорее подтверждает аргументы Нан Зет Да.
Во время лекции Анастасия Бонч-Осмоловская допустила досадную (и принципиальную!) неточность, заявив, что большее число событий наблюдается не в бульварных, а в малоизвестных романах, что являлось бы куда более неожиданным и нетривиальным результатом. Однако в самой работе показано как раз обратное: известность романа не имеет ровно никакого отношения к количеству событий в нем.
Остужающее излишний энтузиазм выступление не повлияло на общее настроение участников школы — все они разбежались по самым разнообразным практикумам и тьюториалам в диапазоне от анализа эмоциональной нагруженности дневников проекта «Прожито» до структуры домашних страничек городской сети Томска и попыток анализа эмоций по видео. Результаты наиболее успешных из них будут представлены в партнерском тексте проекта «Системный Блокъ».
Общим вопросам современных вычислительных технологий была посвящена лекция аспиранта Университета Осло Андрея Кутузова. Он рассказал о современных нейросетевых методах, используемых для моделирования смысла слова, которые в последний год сменяют еще недавно общепринятый word2vec: они не только сопоставляют слову наборы «ассоциаций», но и «замечают» его различные значения.
Проведенная в рамках школы мини-конференция, к сожалению, содержательностью не отличалась и представляла собой набор случайных студенческо-аспирантских докладов. Из них лишь первые два (о семантике слова «поэзия» в русской поэзии и анализ 9-й кантаты Антиоха Кантемира на предмет реального авторства) можно назвать вполне содержательными — да и они современные цифровые техники, в общем-то, не использовали. Желание организаторов предоставить площадку для высказывания студентам, заинтересованным в изучении новых вычислительных методов, конечно, понятно — однако полное отсутствие как отбора, так и попыток разбавить доклады начинающих чуть более «продвинутыми» работами кажется довольно противоречивым решением.
Полноценные же исследования в области digital humanities были представлены на школе двумя выступлениями: видеолекцией Романа Лейбова (Тарту) об образе Крыма в современной русскоязычной «народной» поэзии (на базе текстов с портала «Стихи.ру») и исследованием образов животных в раннесредневековой поэзии Китая.
Совместный проект Романа Лейбова и Бориса Орехова (ГУ ВШЭ) состоит в сравнении и выделении основных тем, связанных с Крымом, в поэтическом национальном корпусе русского языка и в текстах с сайта «Стихи.ру» различных периодов: до начала конфликта вокруг Крыма, в период его острой фазы (февраль 2014-го — февраль 2015-го) и в последние полтора года.
Основной вывод следующий: если для профессиональных поэтов XIX–XX столетий «военно-патриотический» компонент восприятия Крыма был значим всегда (более того, с ним было связано 4 из 5 основных выделенных тематик), то в поэзии народной он стал заметен лишь в связи с появлением крымского конфликта в медиа и оказался полностью синхронизирован с медийной же повесткой.
Если в 2014 году «народные» поэты писали про войну между братскими народами, западных захватчиков и воссоединение с Россией, то с начала 2018 года их больше интересовала война на Донбассе, строительство Крымского моста и, конечно, юбилеи аннексии.
Исследование, по мнению его авторов, указывает на тот факт, что авторы сетевой поэзии мало ориентированы на поэзию профессиональную — даже в виде советского официоза и русской классики, которые доминируют в национальном корпусе, но реагируют скорее на представленные в их непосредственном окружении элементы массовой культуры (от телевизионных новостей до популярных эстрадных песен).
Коты и верблюды в средневековом Китае
Аспирантка Цюрихского университета Мариана Зорькина рассказала о своем цифровом исследовании «поэзии о вещах» времен китайской династии Тан (618–907 годы н. э.).
Из классической литературной критики известно, что средневековые китайцы мало интересовались котами, однако ели их и использовали их шкуры для пошива одежды. Домашние коты считались ленивыми, а приход кота был плохой приметой — к бедности.
Зато они любили тигров, которых считали отгоняющими злых духов «царями зверей», и почитали мифических единорогов (помесей коня, оленя, быка и рыбы с несколькими рогами) — символов кротости и добродетели. Мыши же, по мнению поэтов, приносили счастье и всегда возвращали долги.
При помощи системы word2vec, а также тематического моделирования Мариана изучила корпусы текстов эпохи, состоящие из более чем 40 тысяч стихотворений, и выделила основные характеристики животных, свойственных поэзии тех времен. Вычислительное исследование всего корпуса поэзии подтвердило известные результаты, а также позволило установить некоторые другие.
Например, она измерила относительную близость разных животных к понятиям «дорогой» и «дешевый» (ценными оказались единороги, слоны и верблюды, а дешевыми — обезьяны, лисы и ослы) и выяснила, кого из животных система word2vec выделяет в качестве источников зловония (свиньи, собаки, тигры и зайцы) и приятных ароматов (обезьяны и верблюды).
При помощи тематического моделирования Мариана Зорькина классифицировала животных по типу стихотворений, в которых они встречаются: так, верблюды оказались связаны с международными отношениями, гиббоны — с грустью их ночных криков, а олени, бараны и единороги — с бессмертными.
К сожалению, культурологическая интерпретация полученного материала в докладе была ограниченной, и он во многом был перечислением конкретных вычислительных результатов. Впрочем, рассказ был посвящен непосредственно проводимой работе, часть данных была получена прямо на школе и, очевидно, многое исследовательнице сделать еще предстоит.
Выводы и перспективы
Школа в целом вызывает противоречивое впечатление. Конечно, крайнее уважение вызывает высокий энтузиазм ее участников, до глубокой ночи осваивавших новые вычислительные методики и работавших над своими групповыми проектами совместно с тьюторами.
Однако амбиции школы выше, чем у обычного образовательного мероприятия одной из исследовательских групп. Она претендует на то, чтобы стать наследницей знаменитых летних школ по вторичным моделирующим системам, которые проводились Ю.М. Лотманом в эстонском Кяэрику, c перерывами в период с 1964-го по 1975 год и были «точкой сборки» Московско-тартуской семиотической школы — одного из центральных феноменов позднесоветских гуманитарных наук. Эту высокую планку (тем более в ее современном, глобализированном варианте), к сожалению, мероприятие пока взять не может.
Международное участие ограничивается докладами дружественных русскоязычных аспирантов и выступлением Романа Лейбова — «второй», тартуской стороны в «московско-тартуском» проекте.
Лекции носят глубоко частный характер отчета о конкретных вычислительных работах, в которых, безусловно, важные и интересные экспериментальные результаты не сопровождаются равными по значимости попытками концептуализации и контекстуализации.
Не является ли эта ситуация отражением общей проблемы цифрового литературоведения, которое производит всё новые методики и конгломераты важнейших экспериментальных данных, но провисает в их теоретическом осмыслении? Ведь любая естественная наука, по образцу которых адепты digital humanities пытаются выстроить гуманитарные области, обладает не только набором экспериментальных методик, но и серьезнейшей теоретической базой, которая определяет то, какие эксперименты и в каких условиях разумно проводить, как именно их результаты имеет смысл интерпретировать, а также то, как из этих разрозненных результатов собрать общую картину изучаемого явления.
Быть может, именно появление новых «больших теоретических подходов» (которые, кстати, деятели исходной тартуской школы активно пытались создавать) позволит научиться глубже понимать полученные экспериментальные данные и придаст им характер важного нового знания.