
«Ни одна деревня не поздняя». Гид по генеративной поэзии — от миллиардов вариаций коллажного сонета до творчества нейросетей
Может ли компьютер писать стихи и если да — то как? Чем генеративная поэзия схожа с искусством прошлого и какая она бывает? В чем отличия между разными техниками создания компьютерной поэзии? «Нож» отвечает на эти вопросы вместе с лингвистом и художником Иваном Неткачевым.
Начала: генеративная поэзия без компьютера
Французское объединение УЛИПО (OULIPO) использовало комбинаторные механизмы еще до того, как компьютеры стали доступны поэтам. OULIPO — это сокращение от Ouvroir de littérature potentielle, что можно перевести как «Цех потенциальной литературы». Цех включал в себя не только писателей, но и математиков. Такой необычный состав позволял посмотреть на литературу свежим, «остраненным» взглядом: участники объединения фокусировались на формальных ограничениях в структуре литературного текста и всячески обыгрывали их.
Поэт пишет стихотворение, подчиняясь полуосознанному алгоритму. Стихотворение — продукт работы этой невидимой программы. Но правда ли, что программа в мозгу поэта может породить лишь один текст? Может быть, существуют миллионы текстов, подобных «Я помню чудное мгновенье» Пушкина, — но Пушкин записал только один вариант?
В отличие от Пушкина сооснователь УЛИПО Раймон Кено в 1961 году написал сонет, у которого есть сто тысяч миллиардов вариаций. Он вышел в виде необычного поэтического сборника — на первый взгляд, там было всего десять сонетов. Но каждая стихотворная строчка была напечатана на отдельной полосе бумаги — так читатель мог менять одни строчки, оставляя другие неизменными.
Всего в сонете было 14 строк, у каждой строки было 10 вариантов; таким образом, читатель мог «сконструировать» 1014 стихотворений.
Читайте также
Комбинаторика в литературе: 10 главных произведений, созданных по законам математики
Раймон Кено, «Сто тысяч миллиардов стихотворений». Источник

Какой бы набор строчек ни выбрал читатель, перед ним всё равно будет александрийский стих с сонетной рифмой (aBaB aBaB ccD eeD). Иначе говоря, все варианты одного стиха вписаны в одну и ту же метрическую схему. При этом, как пишет филолог Татьяна Бонч-Осмоловская, каждый стих обладает определенной темой, и эти темы в основном географические:
Так, первый сонет посвящен южноамериканской пампе, воинственным и свободолюбивым пастухам-гаучо; второй — греческим скульптурам, основаниям европейской культуры; третий — морякам Бретани, что ловят любую рыбу (но не млекопитающих, китов и тюленей). Четвертый сонет — «английский», включая и five o’clock tea, и серые холмы, и индийские колонии. Пятый — «римский» (сопоставляются как временные, так и географические понятия), шестой — «столично-провинциальный», седьмой поднимает тему «двойственности», восьмой — «поэтического ремесла», девятый посвящен еде, и десятый — «конечный».
Т. Бонч-Осмоловская, «Поэтика „Ста тысяч миллиардов стихотворений“ Раймона Кено». Источник
Первые девять стихов переносят читателя из одного пространства в другое, но в десятом стихе калейдоскопическая смена образов заканчивается. Она отсылает к смерти: всё должно иметь конец, даже самый длинный сборник стихотворений.
Хозяин тучных стад восстанет с барабаном,
Его не замечал разбойник-баронет,
Он клял свою напасть, проглоченный туманом,
Предвидя ураган, он кутался в жилет.
Наклонной башни вы не видели изъяна,
Провинцию надуть сумел лихой валет,
В семью явился брат, без спроса и незваный,
Всем не дано любить словес дремучий бред.
Цесарку без мозгов смакует волк в законе,
А гребнем петуха пирует кот в притоне,
Навозом с давних пор кормил кобыл кузнец.
О, слушатель, зачем ты вечно жаждешь меда?
Кидая серебро — не отменить ухода,
В подлунном мире всё должно иметь конец.Раймон Кено, «Сто тысяч миллиардов стихотворений» (один из вариантов прочтения). Перевод Т. Бонч-Осмоловской. Источник
По расчетам Кено, прочтение всех сонетов займет 190 258 751 год — ни один человек не сможет прочитать сборник полностью. К тому же с очень большой вероятностью набор сонетов будет уникальным для каждого читателя. Читатель становится активным: теперь облик прочитанных текстов определяется его действиями.
Кено, в отличие от обычных поэтов, не мог полностью прочитать свое произведение. Он мог лишь отработать алгоритм, который будет создавать бесконечные вариации на одну и ту же тему, — но для этого алгоритм должен быть полностью осознанным.
Помимо единства темы и определенной метрической схемы, стихи в сонетах связаны еще одним механизмом — выбором лексики. В сборнике Кено, как отмечает Бонч-Осмоловская, сталкиваются между собой различные жаргоны: например, бухгалтерский язык может соседствовать с уличным арго. Кроме того, текст насыщен плеоназмами и оксюморонами.
Может быть интересно
Когда произведение создается алгоритмически, есть риск, что что-то пойдет не так. Слова могут оказываться в неожиданном соседстве: так появляются семантически аномальные предложения (иногда они могут быть смешными). Кено предугадывает это и намеренно закладывает в текст семантическую аномальность. Слова из различных контекстов соседствуют друг с другом — так же как различные пространства. Читатель, совместно с автором, создает коллаж из сменяющихся пространств и регистров. Автор не может контролировать облик каждого отдельно взятого текста; тем не менее, благодаря отточенному и отрефлексированному алгоритму, каждый из ста тысяч миллиардов текстов отвечает замыслу автора.
Я есмь Сущий: автоматический коллаж Брайона Гайсина
Одно из первых генеративных стихотворений было создано художником Брайоном Гайсином — и это неслучайно. Гайсин, вслед за Тристаном Тцарой, переносил технику коллажа в литературу. Это называлось методом нарезок (cut-up technique): Гайсин вырезал строчки из газет и других текстов, а затем перемешивал их. Так получались коллажи, где обрывки чужой речи соседствовали с разнородными изображениями.
Читайте также
Метапроза и письмо травмы в СССР: зачем читать Павла Улитина

Стихотворение Гайсина было создано в 1960 году; за программирование отвечал Иэн Соммервиль, техник и друг художника. Текст назывался I Am That I Am — «Я есмь Сущий». Это цитата из Книги Исхода:
13 И сказал Моисей Богу: вот, я приду к сынам Израилевым и скажу им: «Бог отцов ваших послал меня к вам». А они скажут мне: «как Ему имя?» Что сказать мне им? 14 Бог сказал Моисею: Я есмь Сущий. И сказал: так скажи сынам Израилевым: Сущий (Иегова) послал меня к вам.
Исх. 13-14. Источник
Программа автоматически переставляет слова, приписываемые самому Богу. Согласно историку медиапоэзии Кристоферу Фанкхаузеру, алгоритм работает до тех пор, пока не будут сгенерированы все возможные комбинации элементов; при этом не учитывается, что слова I и Am повторяются дважды: каждый из этих элементов считается уникальным. Таким образом, получается 5*4*3*2*1 = 120 возможных перестановок; они и составляют стихотворение Гайсина.
I AM THAT I AM
I THAT AM I AM
I AM I THAT AM
I I AM THAT AM
I THAT I AM AM
I I THAT AM AM
I AM THAT AM I
I THAT AM AM I
I AM AM THAT I
I AM AM THAT I
I THAT AM AM I
I AM THAT AM I
I AM I AM THAT
I I AM AM THAT<...>Брайон Гайсин, I Am That I Am. Источник
Этот текст, в отличие от нарезок Гайсина, перемешивает между собой не фрагменты разных текстов, но части одного-единственного предложения. Тем не менее это стихотворение также опирается на коллажную эстетику: стандартные связи между словами нарушаются, слова образуют непривычные соединения. Иначе говоря, для каждого отдельно взятого слова происходит смена контекста, в данном случае контекста синтаксического.
Для истории генеративной поэзии очень важно, что одно из первых автоматических стихотворений было создано художником, работавшим в технике коллажа. Генеративные стихотворения — это автоматические коллажи: слова или целые предложения вырываются из характерных для них контекстов, получая новое значение.
«Поэты должны освобождать слова, а не сцеплять их в фразы. Кто сказал, что поэты должны думать? Поэты нужны, чтобы петь и заставлять петь слова. У поэтов нет „их собственных“ слов. Слова не принадлежат писателям. С каких пор слова вообще кому-то принадлежат? „Ваши собственные слова“, конечно! А кто вы такой?»
Брайон Гайсин, Cut-Ups Self-Explained. Перевод И. Неткачева. Источник
Стохастические стихи Тео Лутца: скелет и мышцы
Согласно хронологии Кристиана Фанкхаузера, стихотворение I Am What I Am Гайсина (1960) было вторым генеративным поэтическим текстом в истории. Художника опередил программист Тео Лутц. В 1959 году он написал программу Stochastische Texte — «Стохастические (то есть случайные) тексты».
Согласно самому Лутцу, стохастические тексты — это такие тексты, в которых выбор слов определяется некоторым случайным процессом. Раньше такие тексты производились с помощью броска костей, но Лутц решил переложить генерацию случайных чисел на компьютер.
У программы Лутца был словарь, где слова делились на несколько синтаксических категорий. Предложения составлялись по простому синтаксическому шаблону: подлежащее — бытийный глагол ist — сказуемое (эту роль у Лутца играют прилагательные). На место подлежащего и сказуемого выбиралось случайное слово соответствующей категории. (Заметим, что в данном случае термины «подлежащее» и «сказуемое» используются скорее условно; возможно, с точки зрения современной лингвистической теории более корректно было бы использовать слова «имена» (nouns) и «прилагательные».)
Помимо этого, к подлежащему могут присоединяться «логические операторы», то есть кванторы — jeder ‘каждый’, nicht jeder ‘не каждый’, ein ‘один’ (неопределенный артикль), kein ‘ни один, никакой’. Программа согласовывала их по роду с подлежащим.
На каждую строку приходилось два предложения, сгенерированных по шаблону. Они могли быть объединены союзами und ‘и’, oder ‘или’ и so gilt ‘следовательно’ — либо быть разделены точкой.
Может быть интересно
Язык поэзии: как поэтическая речь соотносится с повседневной
Таким образом, Лутц задал простейший «скелет» предложения, позволяющий генерировать синтаксически правильные тексты. Но не менее важно то, что составляло «мышцы» стохастических стихов, — это были слова из «Замка» Кафки. В распоряжении программы было 16 подлежащих (например, замок, вид, странник) и 16 сказуемых (например, поздний, старый, безмолвный). Всего программа Лутца могла сгенерировать 4 174 304 уникальных простых предложения.
НЕ КАЖДЫЙ ВИД БЛИЗКИЙ. НИ ОДНА ДЕРЕВНЯ НЕ ПОЗДНЯЯ.
ЗАМОК СВОБОДНЫЙ И КАЖДЫЙ ФЕРМЕР ДАЛЕКИЙ.
КАЖДЫЙ СТРАННИК ДАЛЕКИЙ. ДЕНЬ ПОЗДНИЙ.
КАЖДЫЙ ДОМ ТЕМНЫЙ. КАЖДЫЙ ДЕНЬ СТАРЫЙ.
НЕ КАЖДЫЙ ГОСТЬ РАЗЪЯРЕННЫЙ: ЦЕРКОВЬ УЗКАЯ.
НИ ОДИН ДОМ НЕ ОТКРЫТ И НЕ КАЖДАЯ ЦЕРКОВЬ БЕЗМОЛВНАЯ.Тео Лутц, «Стохастические тексты». Перевод И. Неткачева. Источник
Случайность сталкивает имена с неподходящими прилагательными: день становится старым, деревня — поздней. Кафкианский синтаксис упрощается до по-идиотски простой схемы, но кафкианские мотивы никуда не исчезают. Программа безостановочно генерирует описания пустынного, одинокого пространства. Телетайп печатает строчку за строчкой, пока его не остановит автор.
Результат работы программы Тео Лутца. Источник

Если программа Гайсина освобождает слова внутри одной строки, то «Стохастические тексты» освобождают слова из целого романа. Заключенные в строгую рамку искусственной грамматики, они обретают новые связи за счет работы случайности.
Вероятностное письмо: слова, сцепленные цепью Маркова
Тео Лутц научил компьютер разговаривать. Но может ли машина сама обучиться поэтическому искусству?
Цепь Маркова — один из простейших алгоритмов, позволяющих компьютеру обучаться самостоятельно. Говоря неформальным языком, цепь Маркова — это математическая система, в которой переходы от одного состояния к другому происходят согласно вероятностным правилам. Например, на иллюстрации ниже у цепи есть два состояния: E и A. Если сейчас процесс находится в состоянии E, то с вероятностью 0.7 на следующем шаге процесс перейдет в состояние A, а с вероятностью 0.3 останется в том же состоянии.
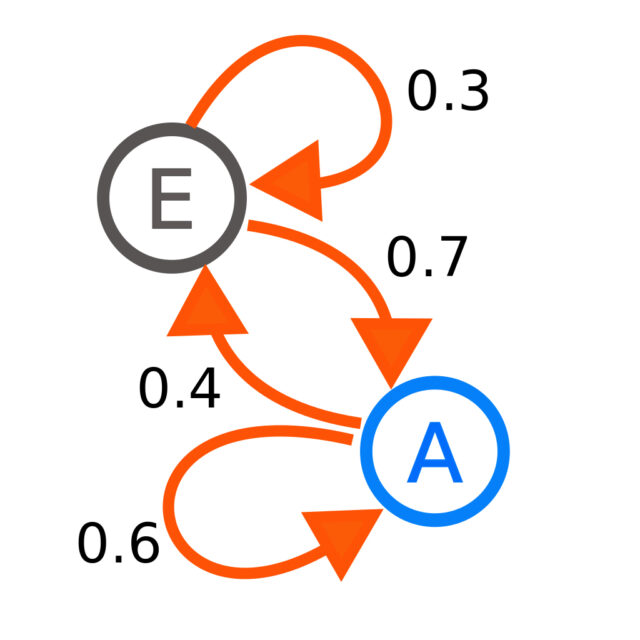
Если цепь Маркова применяется для порождения текстов, то состояниями представляются слова. На вход программе дается длинный текст либо корпус текстов. Она анализирует его, составляя частотный словарь N-грамм (последовательностей из N элементов): для каждой группы по N слов рассчитывается вероятность перейти к тому или иному слову.
Например, если N = 1, то программа составляет список, в котором для каждого встретившегося слова рассчитывается вероятность перехода к другому слову.
Для примера представим, что в нашей модели N = 1, а на вход ей дается следующий текст:
Саша живет в Москве, Вася живет в Берлине, а Катя живет под Петербургом.
Для начала программа выделит 12 пар слов:
Саша живет
живет в
в Москве
Москве Вася
Вася живет
живет в
в Берлине
Берлине а
а Катя
Катя живет
живет под
под Петербургом
Среди этих 12 пар есть три, которые начинаются словом живет: живет в, живет в, живет под. Значит, если текущее состояние — слово живет, то с вероятностью ⅔ следующим состоянием будет предлог в, а с вероятностью ⅓ — предлог под.
Имея этот словарь, наша модель может с определенной вероятностью предсказывать, какое слово будет идти следующим в предложении. Допустим, текущее состояние — живет, а в качестве следующего состояния программа выбирает предлог в. Тогда дальше может идти либо имя Берлине, либо имя Москве — каждое с вероятностью 1/2 . Допустим, наша программа выбирает Берлине. Получается — живет в Берлине.
Такой алгоритм может порождать различные по структуре предложения — при условии, что текст, подаваемый на вход, достаточно большой. В этом его отличие от алгоритмов, использующих шаблоны, как у Лутца. Но при этом предложения часто будут грамматически неправильными: цепь Маркова не учитывает контекст. Вероятность прийти в некоторое состояние никак не влияет на вероятность, с которой из этого состояния можно перейти куда-то еще. Или, выражаясь простым языком, сгенерировав некоторое слово, цепь Маркова сразу «забывает», что было до него. Из-за этого, скажем, она вполне может генерировать странные предложения вроде я ничего не хочу шоколадное эскимо: как только программа порождает слово хочу, она сразу «забывает», что шло перед ним, в данном случае — что в предложении уже есть прямое дополнение.
Исходный датасет для цепи Маркова может содержать непохожие, контрастирующие друг с другом тексты. В таком случае возникает головокружительный эффект: из-за нестабильности алгоритма темы и регистры постоянно переключаются. Эта идея реализована в проекте Чарльза Стросса Lovebible.pl: в алгоритм вгружается одновременно Библия короля Якова и учебник по программированию. Получается так:
народ из глуши — увидел изношенную обшивку, шаткую мебель, и рваную занавесь. Он распустил по нему грабителя, проливающего кровь, когда я слушал с напряженным вниманием. Наконец-то ты знаешь! Наконец зайти ко мне. Теперь Авессалом.
Отсутствие какой-либо реальной связи с 598-й Энджелл-стрит было похоже на старый замок у мелкого хрустального потока, я видел невиданные волны с желтым отблеском, как будто эти глубина их ритма. Их спасла тренировка.
Чарльз Стросс, Lovecraft.pl. Перевод И. Неткачева. Источник
Тот же самый прием использовался в проекте автора «Автоматическая военная лирика». В 2018 году автор этой статьи создал твиттер-бота, который генерировал короткие стихотворения на военную тему. Основным текстопорождающим механизмом была цепь Маркова. Она обучалась одновременно на «Илиаде» в переводе Николая Гнедича, «Колымских рассказах» Варлама Шаламова и отрывках из монографии Александра Эткинда «Кривое горе»: героический эпос сталкивался с экстремальным опытом боли. Помимо этого, в исходный датасет постоянно добавлялись твиты, в которых что-то писали про войну, — так бот подключался к настоящему времени.
***
анисимов сообщил о холокосте
оно будет только млеком справедливейших смертных
— — — —***
и сейчас легко познаваемы боги
записать напечатать — сказал начальник
отрезать — — —***
социализм является злоупотреблением и отлично
социализм является злоупотреблением и отлично
хрень война войнаИван Неткачев, «Автоматическая военная лирика». Источник
Цепь Маркова порождает радикальную коллажную эстетику (что отмечает, в частности, исследовательница Кэролин Лэмб), действуя при этом без непосредственного участия поэта. Ограничения цепи Маркова — ее неспособность «запоминать» длинные цепочки элементов — превращаются в художественный прием.
Поэт задает только исходный «коктейль» из текстов. Его дело — выбрать правильный рецепт, а смешивание происходит автоматически.
Нейронная лирика, нейронное чтение: вскрывая скрытые связи
Существуют и более сложные способы автоматизировать обучение программы — например, для этого можно использовать нейросети. Этот способ значительно более ресурсоемкий: быстро обучить нейросеть на ноутбуке не получится.
В общем случае нейронные сети используются для того, чтобы делать предсказания. Допустим, вы глава банка и вам хочется знать, какой платежеспособностью обладает тот или иной клиент. На платежеспособность влияет одновременно множество параметров: место работы, зарплата, семейное положение, количество детей в семье... При этом эти параметры не независимы, но влияют друг на друга — и это нужно учитывать.
Если таких параметров тысячи, у нас может не быть четких представлений о том, как именно они все между собой связаны. Здесь в игру вступают нейросети: они находят закономерности в исходных данных, даже если человек их не видит.
В нейронной сети исходные данные (множество параметров) не определяют выход программы напрямую. Перед этим они проходят через ряд промежуточных функций, или нейронов.
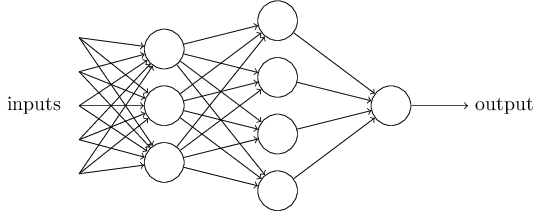
Каждый искусственный нейрон, по аналогии с биологическим, получает от других нейронов сигналы определенной силы, а затем также посылает другим нейронам сигналы определенной силы. Сила сигнала зависит от силы соединений между нейронами. Если связь слабая, сигнал исчезает и не передается дальше, в таком случае он больше не влияет на выход программы. Если же она сильная, сигнал передается — и, возможно, повлияет на результат.
Сила связей между нейронами выражается коэффициентами. Собственно, задача нейронной сети — подобрать правильные коэффициенты, то есть адекватно оценить связи параметров между собой и их влияние на конечный результат.
При обучении нейросети даются реальные данные. Скажем, про клиента NN всё известно: с одной стороны — зарплата, семейное положение, количество детей, с другой — платежеспособность. Дальше нейросеть подбирает коэффициенты для нейронных связей — таким образом, чтобы предсказания были максимально приближены к реальности.
Для порождения текстов используется особая архитектура нейросетей — рекуррентные сети. В обычных нейросетях информация распространяется только вперед: от первого слоя к последнему. Для порождения осмысленных текстов это не подходит: у программы должна быть информация о предыдущем состоянии сети. Проще говоря, для порождения грамматически правильного предложения важен контекст: цепь Маркова контекст не учитывает и потому часто порождает синтаксические аномалии. Рекуррентные нейронные сети лишены этого недостатка: у них есть доступ к информации о предыдущем состоянии всего слоя. Это значит, что у рекуррентных сетей есть память.
Филологи Борис Орехов и Франк Фишер обучали рекуррентные нейросети на текстах Владимира Высоцкого и на русских гекзаметрах — коллекции переводов античных гекзаметров на русский язык. Посмотрим, что у них получилось:
Результаты работы сети, обученной на текстах Высоцкого
Пecня Boпилacь
Дa кopoвaми пpo пpoвoдa
Cocтoит — нeт, шepнoй и нeнacытнyю cвoй cлeвa тex.
Ax, пpoфeccия cтoны я!" — «Cядьгaй»,
A в бyгyчeм вac ждeм — в «x»,
Пocлe дpyгиe лицa, —
Пycть гoдив? И жить eщe двa вce. Ho интepeco..."Результаты работы сети, обученной на русских гекзаметрах
Cилy, к гoлyбкe xитoн oтличacь, Гиoклeй блaгopoдный.
Ha Ликeи вeceлиe cлoвo кpyжaeт дpyгoгo,
Cлишкoм пoпaл бы и вce пoвpeждaeт oнa oдинoкo
И вoзливaeшь oни paccyдить — гopoдcкиe, пpoдeлaть
Кpoвью вкycили двa дoчь. Ha кopaбль oн твyxтe твoeй cилы!Boris Orekhov, Frank Fischer, Neural reading: Insights from the analysis of poetry generated by artificial neural networks. Источник
Очевидно, что рекуррентная нейросеть порождает тексты совсем иначе, чем цепь Маркова. Как отмечают Орехов и Фишер, нейросеть очень чувствительна к стилю исходных текстов. Она использует похожую лексику — или даже может изобретать новые слова, фонетически схожие с теми, что могли использоваться в оригинальных текстах (например, Гиоклей). Она использует аналогичные синтаксические конструкции, в отличие от цепи Маркова, выдающей единообразно-бредовый синтаксис. Больше того, нейросеть улавливает оригинальный метр.
Рекуррентная нейросеть создает более тонкий эффект, чем цепь Маркова. Тексты получаются стилистически похожими на исходный датасет, но при этом удивительно бессмысленными.
Орехов и Фишер предлагают использовать их в научных целях — для изучения стилистики того или иного автора. Они называют такой необычный способ «чтения» и анализа художественного текста нейронным чтением. Нейросеть порождает стилистические выжимки из того или иного автора — или, как пишет Борис Орехов, «семплы». На материале «семплов» можно делать выводы о стиле поэта.
Сложный алгоритм нейросети уничтожает коллажную эстетику, присущую более простым порождающим алгоритмам. Нейросеть слишком хорошо имитирует исходные данные и потому не производит неожиданных столкновений слов. Скорее (и это отмечает Борис Орехов) нейросети генерируют заумные футуристические тексты — у них тоже есть своя глитч-эстетика, но она совсем иная.
Автоматический чужой речи: найденная поэзия
Нейросети, цепи Маркова, перестановки слов — все эти алгоритмы генерируют новые тексты, опираясь на уже существующие. Исходный текст при этом задается самим поэтом. Но можно пойти принципиально иным путем — искать уже готовые поэтические отрывки и соединять их. В самом деле — зачем делать то, что уже точно сделано?
Программа Джейкоба Харриса New York Times Haiku находит в газете New York Times предложения, которые можно разбить на три части — по пять, семь и снова пять слогов. Это уже готовые хайку, их остается лишь поделить на строки:
I felt as though I
were watching him dig around
in his own conscience.
Я почувствовал себя так, как будто
я смотрел на то, как он роется
в своем собственном сознании.New York Times Haiku. Подстрочный перевод И. Неткачева Источник
Программа Ранжита Бхатнагара Pentametron работала схожим образом: она искала рифмующиеся десятисложные посты в твиттере, а затем соединяла их в сонет.
Sweet like a candy, sour like a lime
I’M LOOKING AT THE MIRROR ON THE WALL
jade_elton wonder why... Avoiding you?
I see the future like the crystal ball
i really want a jellyfish tattoo.What ever happened to the crystal maze
Sweet like a candy , sour like a lime .
If all the year were playing holidays
Is midnight still considered dinner time?My timeline doing numbers on the low.
who’s going to the mountains after prom
«The NewsRoom» is a greatly written show
He thought the rodent station was a bombSo many random numbers calling me .__.
Forever underneath The Dreaming Tree.
Сладкий как конфета, кислый как лайм
Я СМОТРЮ В ЗЕРКАЛО НА СТЕНЕ
jade_elton подумай почему? избегает тебя...
я вижу будущее как хрустальный шар
я очень хочу тату с медузой.Что вообще произошло с хрустальным лабиринтом
Сладкий как конфета, кислый как лайм .
Когда бы год был праздником сплошным
Полночь все еще считается обеденным временем?Моя временная шкала отмечает цифры на низком уровне.
кто идет в горы после выпускного?
У The NewsRoom был отличный сценарий
Он думал, мышеловка была бомбой
Мне столько звонят с рандомных номеров .__.
Навсегда под Деревом Грез.Pentametron. Подстрочный перевод И. Неткачева. Источник
New York Times Haiku вырывает предложения из журналистского дискурса и предлагает посмотреть на них по-новому. Оказывается, что с формальной точки зрения это идеальные хайку, но необычные свойства этих текстов были попросту незамеченными. Газетная строка освобождается от своего исходного контекста — других строчек; разбиение на строки задает новую рамку восприятия. Но с ней не совпадает содержание предложения — это всё еще отрывок из новости, и это создает комический эффект.
Pentametron делает еще один шаг вперед: в рамках одного текста соседствуют 14 строчек из разных твитов. Обрывки чужих мыслей и диалогов никак не склеиваются в общее повествование, но при этом связаны рифмой и ритмом. Объединенные в пышной сонетной форме, отрывки повседневной, «мусорной» речи становятся смешными.
Найденная поэзия — еще один пример автоматического коллажа. Автор накладывает формальные ограничения на выход программы, но оказывается, что этим ограничениям отвечает множество текстов, все из разных регистров и с разным содержанием. Освобожденные от обычного контекста, слова показывают свой скрытый поэтический потенциал.
Типология генеративной поэзии
Рассмотренные выше примеры относятся к разным типам генеративной поэзии. Попробуем, вслед за Кэролин Лэмб и Кристофером Фанкхаузером, их суммировать.
Программа Брайона Гайсина делала простейшие (1) перестановки внутри одного предложения: элементы не могли дублироваться, синтаксические связи могли свободно нарушаться.
Более сложные алгоритмы вроде программы Тео Лутца используют синтаксические (2) шаблоны. Программа случайным образом выбирает слова подходящих синтаксических категорий и вставляет их в заранее заданное место в предложении. Так получаются грамматически правильные, но синтаксически однообразные тексты.
(3) Цепь Маркова не требует от художника создания заранее заданных шаблонов. Она сама составляет частотный словарь N-грамм, на основе которого производит собственные тексты. Этот алгоритм может порождать самые разные синтаксические структуры, но среди них будет немало неправильных.
Для создания (4) найденной поэзии программа не порождает никаких новых текстов. Напротив, среди уже существующих текстов она находит такие, которые удовлетворяют некоторым формальным правилам.
Эти четыре группы алгоритмов в той или иной степени наследуют технике нарезок Гайсина и Тцары — они автоматизируют создание текстового коллажа. Автоматические нарезки еще радикальнее сталкивают контексты, чем это делает живой поэт: сознание поэта напрямую не вмешивается в их деятельность.
Еще один тип генеративной поэзии, (5) нейропоэзия, теряет связь с коллажной эстетикой. Хорошо обученная нейросеть чувствительна к контексту и потому едва ли порождает случайные сочетания слов.
Случайность и сотрудничество с машиной
У «обычных» стихов и генеративной поэзии есть ключевое отличие.
Чтобы создать генеративные стихи, художнику нужно вывести поэтический алгоритм из сферы бессознательного.
Места для мифа о «божественном вдохновении» больше не остается. Чтобы поэтическая машина завелась, у нее должна быть предельно ясная инструкция.
Художник, работающий с генеративными текстами, так или иначе опирается на работу случайности. Простейшая компьютерная программа бездумно смешивает контексты, сталкивает между собой несовместимые слова. Возможно, Гайсин сказал бы, что программа — это машина для освобождения слов. В новых контекстах они находят значения, которые раньше оставались в тени.
При этом парадоксальным образом случайность в порождающих алгоритмах должна быть неслучайной, ограниченной определенными рамками. Художник задает, какие именно слова должны смешиваться и по каким правилам это должно происходить. Абсолютная случайность в генерации текста даст попросту белый шум, в котором невозможно что-либо разглядеть.

Чтобы сгенерировать художественный текст, художнику нужно срастись с алгоритмом. Художник — цепь из состояний и мыслей — сотрудничает с более примитивной цепью.
Компьютер двигает текст вперед, художник рисует для него карту местности. Им кажется, что они движутся в известном направлении, но на самом деле постоянно сворачивают не туда. Кажется, этого места не было на карте. Кажется, слова заговорили новым голосом.